Este bloque explica los motores de búsqueda de internet. La estructura del módulo es la siguiente:
2.1. Captura de información
2.2. Procesamiento y recuparación de infornación
2.3. Presentación de resultados
Es un capítulo espeso, que me ha costado leer pese a que consta tan solo de siete páginas. Pero el lenguaje científico y con muchos conceptos desconocidos para mí, me han hecho difícil la lectura.
¿Qué me ha quedado claro?
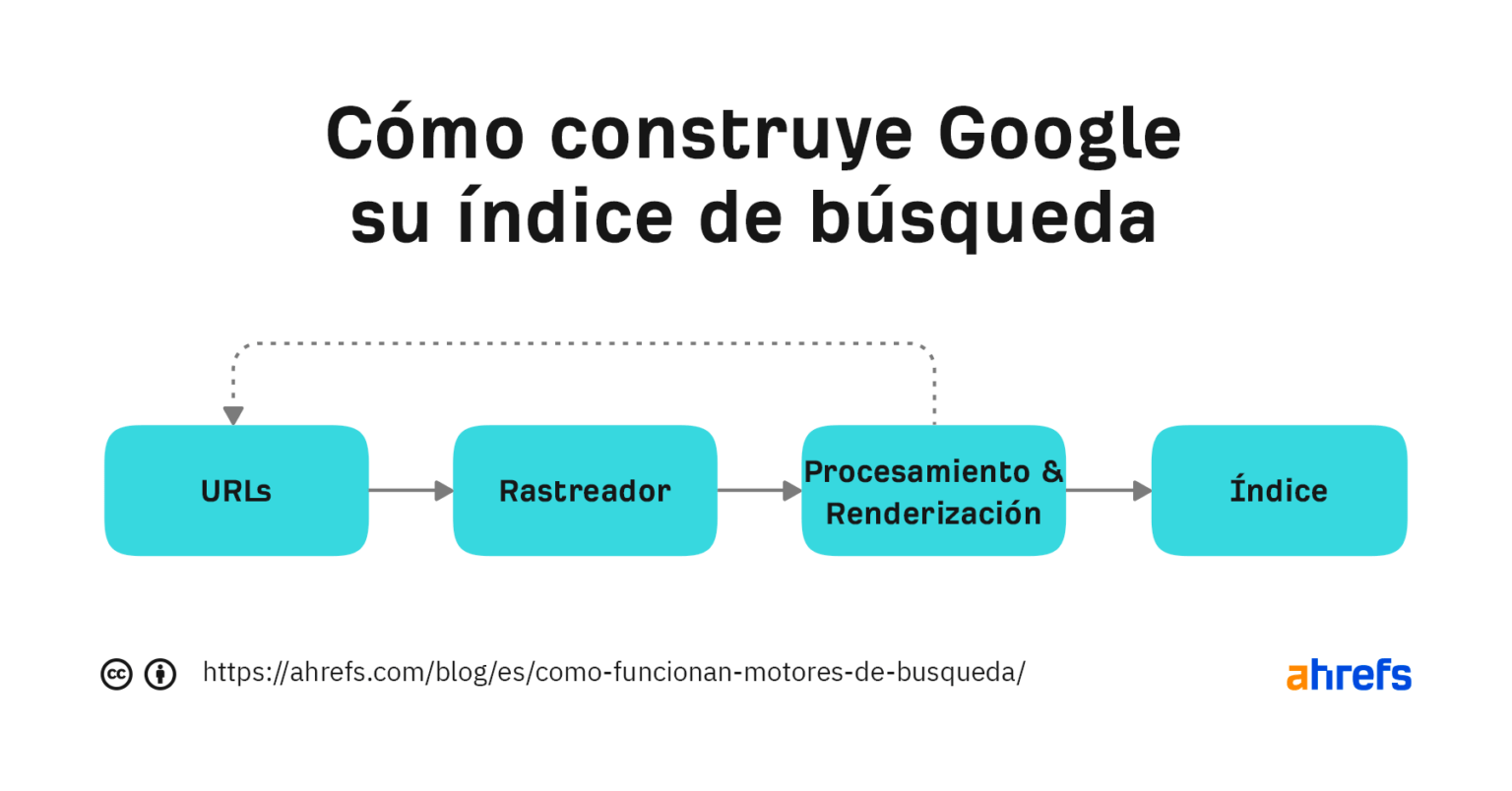
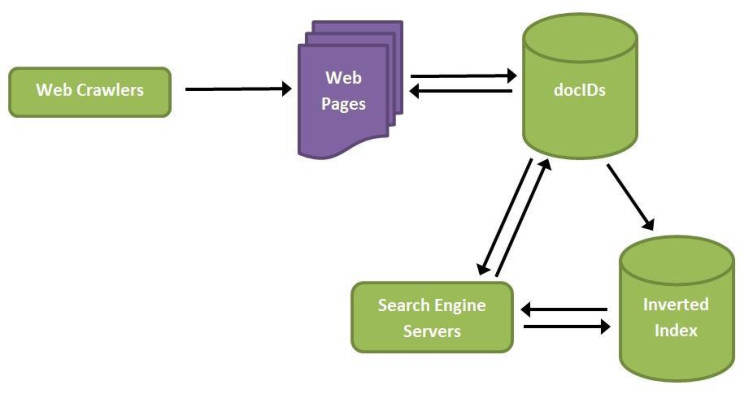
La identificación y la captura de información se lleva a cabo por un robot o spider: "Herramienta de sofware con la finalidad de localizar e identificar nuevs páginas y documentos y detectar modificaciones modificaciones"
Entre 1993 y 1994, se recomendó aplicar un "estándar de facto" (patrón o norma que no ha sido consensuada ni legitimada poe un organismo de estandarización). Por defecto, entiendo de la lectura qye se utilizan las Guías para Autores de Robots y las Normas para la Exclusión de Robots donde se establecen principios de acttividad responsable, eficiencia de utilización de recursos y limitaciones de acceso a servidores.
Un motor de búsqueda es un sofware diseñado para realizar una búsqueda siguiendo una serie de algoritmos e indexando lo que encuentra, a modo de base de datos.
Cada motor de búsqueda tiene una "fórnula secreta" para encontrar la información oculta de la que hablábamos en la primera entrada del curso. Te recomiendo que sigas el enlace que te dejo a continuación, para conocer más a fondo qué, cómo funciona y cuántos tipos exixten.
Los contenidos, fotos y enlaces de esta entrada están sacados del libro de Catedu correspondiente al curso de AulAragón "Estratégias de búsqueda en Internet" (Módulo2) y de la informaciín enlazada.
Este trabajo tiene la licencia CC BY-NC-SA 4.0![]()
![]()
![]()
![]()
No hay comentarios:
Publicar un comentario